刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。
本周开始,AI大模型春晚正式迎来小高潮。
就在刚刚,字节跳动也加入狂欢行列,豆包大模型1.5版正式发布!

豆包大模型1.5的模型基础能力,再次展现出超强进化,在多个公开测评基准中成绩亮眼。
而它的多模态能力,无论语言、视觉理解还是实时语音,也都实现了全面领先。
本就人气居高不下位于Top 3的豆包,带给用户的体验将更上一层楼。
豆包,少数不蒸馏的模型
我们最常见的问题之一——A模型说自己是B模型,就是因为它们「蒸过头」导致的。
少数例外,也就是没有对任何其他模型进行过蒸馏的,就数Claude、Gemini和豆包了。
在「晚点」的专访中,MiniMax的闫俊杰曾表达过这样的观点。
实际上,做一个看上去像o1的模型其实没有那么难,只要蒸馏几千条o1数据就可以了。
这也是为什么在o1发布之后,很多公司都非常快地实现了跟进。
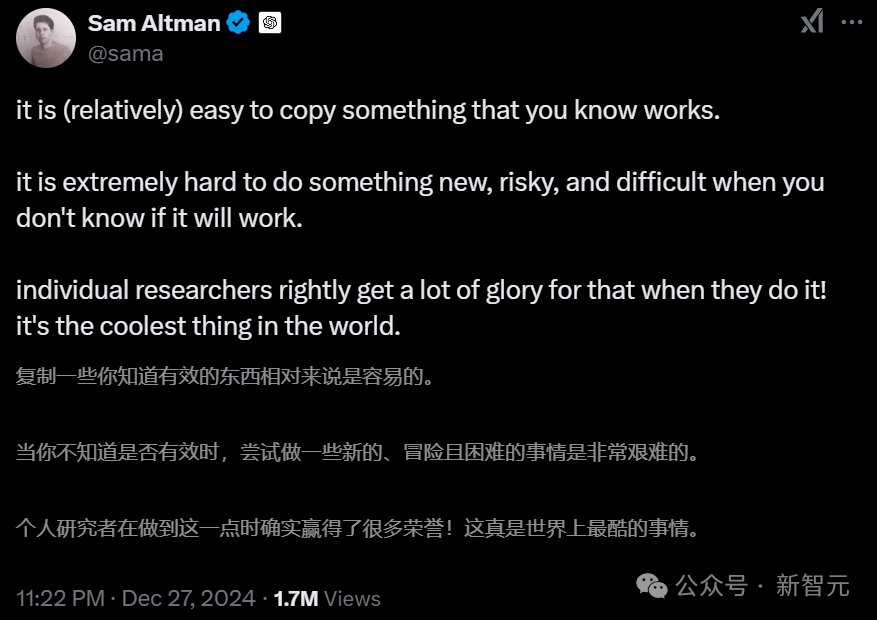
的确,蒸馏是一种路径,但是不是捷径,却不好说。
根据文本模型中存在的「对齐税」,如果一定要把模型去对齐一个别的模型的结果,那必然会有一些能力受限。
相比之下,豆包走的,是一条独属于自己的路。
视觉理解能力超强进化
视觉理解方面,团队这次在多模态数据合成、动态分辨率、多模态对齐、混合训练上进行了全面技术升级,让模型在视觉推理、文字文档识别、细粒度信息理解、指令遵循方面的能力进一步增强了。
而且,模型的回复模式还变得更加精简、友好。
现在,豆包大模型1.5能读懂不同分辨率和不同长宽比的图片,支持百万级分辨率,能更清晰得识别内容。
就比如,手拍题有时因为光线问题,或是像素问题,分辨率不是很高。即便如此,也难不倒豆包大模型1.5。
豆包大模型1.5堪称一款作业神器,那些想要确认解题是否正确的学生们,完全不用等老师、父母纠错了。
AI不仅给出了打分,还详细分析了解题过程,对于错误的题目,还会纠正。




